本文内容
什么是机器学习特征
在机器学习(Machine Learning,简称 ML)中,特征(Feature)是用作 ML 模型输入以进行预测的数据。例如,银行信用卡风险控制模型,在判断某笔交易是否为欺诈时,那么在海外进行的交易可能是欺诈的良好指标之一。
ML 主要在两种情况下使用特征:
- 训练模型阶段,我们需要大量的历史数据。
- 进行实时预测时(也称为在线推理),我们只需要向模型提供最新的特征,但需要在几毫秒内提供。在上面的风险控制例子中,模型只需要知道当前交易是否在国外,但需要即时获取该信息。
什么是特征工程
特征工程(Feature Engineering)是这样一个过程:将数据转换为能更好地表示潜在问题的特征,从而提供机器学习性能。
例如,在信用卡反欺诈模型中,交易发生地区和用户常住国家是否一致,是一个很好的指标。
| 交易ID | 用户常住国家 | 交易发生地区 |
|---|---|---|
| 01 | China | Shanghai |
| 02 | China | HongKong |
| 03 | China | USA |
加工为特征后:
| 交易ID | 是否在国外交易 |
|---|---|
| 01 | False |
| 02 | False |
| 03 | True |
特征工程涉及从原始数据中提取和转换变量,以供模型训练和预测。这个过程需要大量的软件开发工作,包括数据提取和清理、特征创建和存储等步骤。
特征工程中的一些挑战
ML 应用开发的几个典型阶段如下表。
| 阶段 | 关注点 | 主要团队 |
|---|---|---|
| 产品规划 | 用 ML 解决什么业务问题? | 业务和产品 |
| 模型开发 | 哪些特征和算法能更好地预测? | 数据科学家 |
| 工程部署 | 怎么把特征和模型部署到生产环境中? | 工程 |
| 运维 | 怎么保证 ML 应用可靠运行? | 工程和运维 |
在模型开发阶段,数据科学家会进行大量的特征工程,以找到能够实现最高预测精度的特征。一旦该过程完成,他们通常会将项目交给工程同事,后者将把这些特征加工管道投入生产环境。
数据加工管道(Pipeline)是机器学习应用程序的重要组成部分,它们负责将数据从原始状态转换为可用于训练和测试模型的格式。这个过程需要经过数据收集、预处理、转换和清理等多个步骤。数据加工管道的稳定性至关重要,如果出现了问题,那么训练和测试模型的效率和质量都会受到影响,甚至可能导致整个应用程序的失败。
在实践中,实现和管理这些数据加工管道有很大的挑战:
- 由于知识背景和关注点不一样,针对特征加工管道的实现逻辑,数据科学团队和工程团队有较大的沟通成本。
- 技术架构上,涉及数据仓库、流式计算、实时处理等多个基础架构和团队。
- 特征加工,一般涉及到离线训练(线下)和在线推理(线上)两部分,需要保证特征的线上线下一致性,避免出现特征的训练-服务偏差(Training-Serving Skew )。
- 在获取训练集时,必须保证时间点正确性(Point-in-time Correctness),避免特征穿越(Data Leak)。
 特征加工管道的复杂度,类似机械手表的传动装置
特征加工管道的复杂度,类似机械手表的传动装置
特征平台较好地解决了这些特征投入生产的工程挑战,同时带来其他好处。具体来说,特征平台:
- 编排并持续运行数据管道以计算特征,并使其可用于离线训练和在线推理。
- 将特征作为代码进行管理,允许团队进行代码审查、版本控制并将功能更改集成到 CI/CD 管道中。
- 创建特征库,标准化特征定义,使数据科学家能够跨团队共享和发现功能。
特征平台的架构
特征平台利用现有的数据基础架构(如 Hadoop、Spark、Kafka、Redis 等),不间断地将原始数据转换为特征、存储特征和提供特征,从而满足 ML 应用程序的需求。

用户与特征平台交互的方式主要有两种:
- 特征的创建和发现
- 用户定义新特征(使用 Python 代码)。特征定义在git存储库中进行管理。
- 用户发现其他团队定义的现有特征。
- 获取特征
- 离线训练时,用户可以 Notebook 中调用特征平台,获取训练模型所需的所有历史数据(get_offline_features)。特征平台会基于正确的事件时间点连接,生成特征数据,继而供任何模型训练工具(如 XGBoost,Scikit-learn 等)使用。
- 在线推理时,特征平台提供了一个供实时应用程序调用的 REST API,毫秒级返回给定实体ID的最新特征向量,ML 模型将基于该特征向量进行预测。
特征平台主要包括四个组件:特征注册中心、特征加工管道、特征存储库和特征监控。
特征平台核心组件 1:特征注册中心
许多数据科学家在Notebook中进行特征工程。它们是交互式的,易于使用,开发效率高。但是,当这些特征需要投入生产环境时,由于不容易将它们集成到标准的CI/CD开发流程中,开发质量不像传统软件那样可控了。
在特征平台中,特征定义包括三个方面:
- 数据的来源。
- 数据转换逻辑(用 SQL 或 Python 定义)。
- 元数据,例如特征名称和描述,以实现共享和可发现性。
# 定义特征元数据、转换逻辑
avg_transaction_amount = Feature(
name="avg_transaction_amount",
key=account_id,
feature_type=FLOAT,
transform=WindowAggTransformation(
agg_expr="cast_float(transactionAmount)", agg_func="AVG", window="7d"
),
)
# 定义数据的来源
transactions_source = HdfsSource(......)
# 将数据来源和特征关联起来
agg_anchor = FeatureAnchor(source=transactions_source, features=......)
然后,这些特征集中可用,供所有团队在自己的模型中发现和使用。这样可以节省开发时间,在团队之间建立一致性,并节省计算成本,因为不需要针对不同的用例多次计算特征。
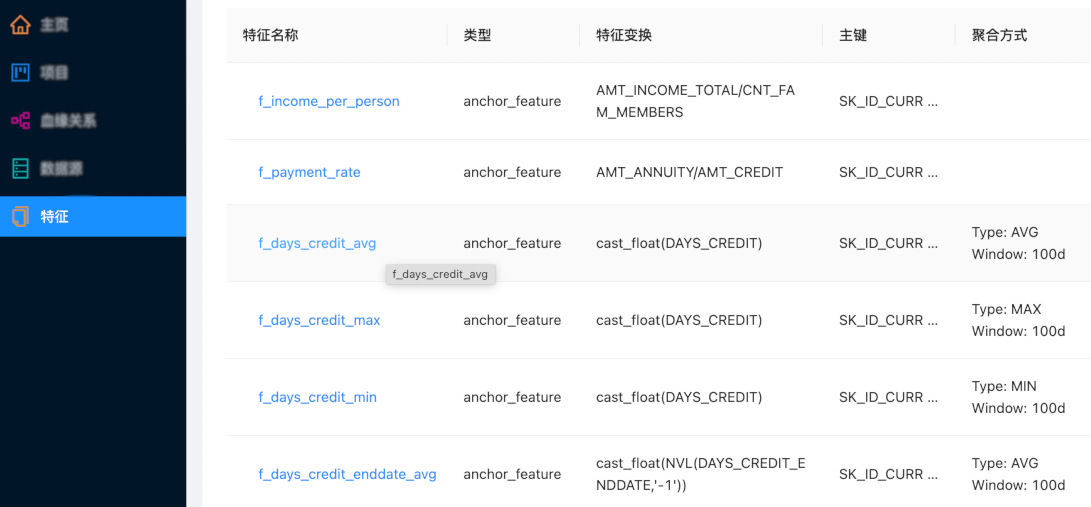
特征平台核心组件 2:特征加工管道
机器学习应用程序需要连续处理新数据,以便模型可以使用最新的数据进行预测。用户在存储库中定义特征后,特征平台将自动处理数据管道以计算该特征。
特征平台一般支持三种类型的数据转换。
| 数据转换 | 定义 | 数据源 | 示例 |
|---|---|---|---|
| 批处理 | 仅应用于静态数据的转换 | 数据仓库、数据湖、数据库 | 每个商家的平均交易金额,每日更新 |
| 流式处理 | 应用于流式处理源的转换 | Kafka, Flink | 过去 30 分钟内的用户交易数,每秒更新一次 |
| 实时处理 | 基于仅在预测时可获取的数据,生成特征变换 | 面向用户的应用程序、RPC服务的API | 当前用户交易金额是否远高于平均交易金额 |
这些转换在特征平台连接到的数据处理引擎(Spark、Python)上执行。
批量转换易于执行,可以通过针对数据仓库的 SQL 查询或通过运行 Spark 作业来执行。但是,ML应用程序从只能通过流式处理和按需转换访问的新信息中受益最多。例如,检测金融欺诈时,使模型能够做出最佳预测的功能将包含有关当前交易的信息(例如金额、商家和位置,或者有关过去几分钟内发生的交易的信息)。
访问新数据将提高大多数模型的性能,而一些企业仍在使用批量转换,只是因为管理流式处理和实时转换很复杂。特征平台将这种复杂性抽象化,允许用户定义转换逻辑并选择是否应将其作为批处理、流式处理或实时转换执行。
在开发阶段迭代新特征时,需要回填数据以生成训练数据集。例如,某个特征需要训练模型的整个时间窗口内回填。特征平台在定义新特征时自动运行这些转换,从而在开发过程中实现快速迭代周期。
特征平台核心组件 3:特征存储库
特征存储库为离线训练和在线推理环境一致地存储和提供特征。
当特征在两个环境中的存储不一致时,模型训练的特征可能与其用于在线推理的特征存在细微差异。这种现象称为训练-服务偏斜,它可能会以无声和灾难性的方式破坏模型的性能,这些方式极难调试。特征存储库保证了两个环境中特征的一致性。
对于离线训练,特征存储库需要包含数月或数年的数据。它存储在数据仓库或数据湖中,如 Hadoop。这些数据源针对大规模检索进行了优化。
对于在线推理,应用程序需要能够超快地访问少量数据。为了实现低延迟查找,这些数据保存在 Redis 或 Cassandra 等在线存储中,一般仅保留了每个实体的最新特征值。
若要脱机检索数据,通常通过笔记 Notebook 友好的 SDK 访问特征值。对于在线推理,特征存储库提供包含最新数据的单个特征向量。虽然每个请求中的数据量很小,但特征存储库必须能够扩展到每秒数千个请求。这些响应以毫秒为单位通过REST接口提供给实时应用程序。高性能特征存储库必须提供有关可用性和延迟的 SLA(Service Level Agreement, 服务等级协定)。
 图2:特征存储库的调用
图2:特征存储库的调用
特征平台核心组件4:特征监控
当ML系统中出现问题时,通常是数据问题。由于特征平台管理从原始数据到模型的过程,因此它们在检测数据问题方面具有独特的优势。特征平台支持两种类型的监控。
数据质量监控
特征平台可以跟踪传入数据的分布和质量。自上次训练模型以来,数据分布是否发生了重大变化?我们是否突然看到更多的缺失值?这是否会影响模型的性能?
运维监控
运行生产系统时,监视操作指标也很重要。特征平台跟踪特征的过时性,以检测数据何时未以预期速率更新,以及与特征存储相关的其他指标(可用性、容量、利用率)以及与特征服务相关的指标(吞吐量、延迟、每秒查询数、错误率)。特征平台还监视特征加工管道是否按预期运行作业,检测作业何时不成功,并自动解决问题。
特征平台使这些指标可用于现有监视基础结构。必须像跟踪任何其他生产应用程序一样跟踪操作ML应用程序,这些应用程序使用现有的可观测性工具进行管理。
特征平台的价值
高效的特征加工
统一、友好的特征加工流程,将让您的日常工作更加高效
特征平台的部分魔力在于它允许 ML 团队快速生产新特征。但是,当特征平台被多个团队使用并为多个用例提供支持时,就会发生价值爆炸式增长。
特征平台允许数据工程师支持更多的数据科学家。一旦特征平台被广泛采用,数据科学家就可以轻松地将已经计算的特征添加到他们的模型中。原来团队需要几个月的时间才能完成部署的工作,1天时间即可以完成。
共享创造更大价值
特征和加工算法集中展示,团队之间能轻松共享
便于审计和监管
可视化的特征展示和监控界面,是给审计和监管部门的展示窗口
及时发现问题
特征质量随时监控,轻松应对业务变化
什么时候采用特征平台?
尽管过去几年整个 MLOps 生态系统蓬勃发展,但当您在技术选型时,应该尽量保持技术栈的简单性,仅在必要时才引入特定的工具。
技术团队在以下情况下使用特征平台更合适:
- 数据科学家和数据工程师之间沟通成本较高,开发和部署特征加工数据管道费时费力。
- 部署的机器学习应用程序需要满足严格的 SLA。
- 多个团队希望拥有标准化的特征定义,并希望不同模型能够复用部分特征。
团队在以下情况下应避免采用特征平台:
- 特征尚处于构思或开发阶段,暂时没有准备投入生产环境。
- 只有一个团队,并且只处理批量数据。