时间点关联(Point-in-time Join)
如果您的特征在建模中不会随时间变化(例如成年人的身高),则时间点确实不是问题。然而,对于大多数特征而言,时间点却是非常重要的因素。例如,一个人的工资和一个人在网站上的购买行为,都会随着时间的推移而发生变化。我们将这些特征称为时间序列特征。
在处理时间序列特征时,确保时间点的正确性是至关重要的。因为时间序列特征的价值和可靠性,往往取决于时间点的准确性。如果时间点不准确,那么依据这些特征所做出的预测或分析,也可能会产生偏差。
特征穿越(Feature Leakage)
模型应该仅使用过去的数据来预测现在,而不能使用未来的数据。如果模型使用未来的数据来进行预测,那么这被称为特征泄漏。
例如,考虑一个时间戳为7天前的观测数据。对于这个数据来说,7天前就是它的现在。然而,如果我们在数据仓库中引入了时序特征数据,其中包含了2天前的最近购买数据,那么这些数据就会被视为未来的特征。
如果我们盲目地使用数据仓库中的最新特征数据,那么我们就会将未来的数据泄漏到模型中。该模型(通常)在训练期间表现得更好,但在在线推理服务时表现不佳。为什么?在线服务期间没有未来的数据。
为了避免这种错误,我们需要确保在模型中使用的数据都是过去的数据,而不能包含未来的数据。这需要我们对数据进行合理的时间戳处理和过滤,以确保模型只使用过去的数据来预测现在。
时间点正确性
时间点正确性可确保不会将未来数据用于训练。它可以通过两种方法实现:
- 如果观测数据(observation data)具有所有观测事件的一个统一的全局时间戳,则只需将要素数据集时间旅行回该时间戳即可。
- 如果观测数据对于每个观测值事件具有不同的时间戳,则需要对每个事件使用时间点联接。
第一种方法更容易实现,但有更多的限制(全局时间戳)。第二种方法提供了更好的灵活性,并且不会浪费任何特征数据。万维探索特征平台使用第二种方法,可以扩展到大型数据集。
基于时间点检索特征
为了说明基于时间点检索特征的强大功能,请考虑以下虚拟场景,其中:
- 跨越多天的样本(观测值)数据
- 跨越多天的特征数据
- 在样本数据中,由于同一用户在不同时间可能有多个响应,因此可能多次出现具有不同标签(响应)的同一“UserId”。在下面的示例中,用户 1 和用户 3 都是重复的(跟踪 ID 分别为 4 和 5):
Label 数据集
| TrackingID | UserId | Label | Date |
|---|---|---|---|
| 1 | 1 | 0 | 05/01 |
| 2 | 2 | 1 | 05/01 |
| 3 | 3 | 1 | 05/02 |
| 4 | 1 | 1 | 05/03 |
| 5 | 3 | 0 | 05/03 |
同时,UserId 上有另一个名称为 X 的特征。假设每天生成此特征:
X 特征数据集
| UserId | X | DateX |
|---|---|---|
| 1 | 0.5 | 2022/05/01 |
| 2 | 0.3 | 2022/05/01 |
| 3 | 0.1 | 2022/05/01 |
| UserId | X | DateX |
|---|---|---|
| 1 | 0.4 | 2022/05/02 |
| 2 | 0.2 | 2022/05/02 |
| 3 | 0.1 | 2022/05/02 |
| UserId | X | DateX |
|---|---|---|
| 1 | 0.3 | 2022/05/03 |
| 2 | 0.2 | 2022/05/03 |
| 3 | 0.15 | 2022/05/03 |
我们希望使用样本数据查找特征,以便对于同一主键,为每个标签提供与过去最接近的特征值。
时间点关联后的返回结果
| TrackingID | UserId | Label | Date | X |
|---|---|---|---|---|
| 1 | 1 | 0 | 05/01 | 0.5 |
| 2 | 2 | 1 | 05/01 | 0.3 |
| 3 | 3 | 1 | 05/02 | 0.1 |
| 4 | 1 | 1 | 05/03 | 0.3 |
| 5 | 3 | 0 | 05/03 | 0.15 |
如上,对于每个跟踪 ID,我们都会根据“日期”列获取最新数据。
特征平台的时间点关联功能
使用上面的示例,您可以通过以下方式定义时间点查找:
UserId = TypedKey(key_column="UserId",
key_column_type=ValueType.INT32)
myXSource = HdfsSource(name="myXSource",
path="abfss://demosource@demosource.dfs.core.windows.net/demosource.parquet",
event_timestamp_column="DateX",
timestamp_format="yyyy/MM/DD")
features = [
Feature(name="f_location_avg_fare",
key=UserId,
feature_type=FLOAT,
transform=WindowAggTransformation(agg_expr="x",
agg_func="LATEST",
window="7d")),
]
point_in_time_anchor = FeatureAnchor(name="features",
source=myXSource,
features=features)
下面是时间点关联查找的代码示例:
feature_query = FeatureQuery(
feature_list=["feature_X"], key=UserId)
settings = ObservationSettings(
observation_path="abfss://{adls_fs_name}@{adls_account}.dfs.core.windows.net/demo_data/green_tripdata_2020-04.csv",
event_timestamp_column="Date",
timestamp_format="MM/DD")
client.get_offline_features(observation_settings=settings,
feature_query=feature_query,
output_path="abfss://{adls_fs_name}@{adls_account}.dfs.core.windows.net/demo_data/output.avro")
Advanced Point-in-time Lookup
我们在同一时间轴上绘制同一实体键的观测数据集和特征数据:
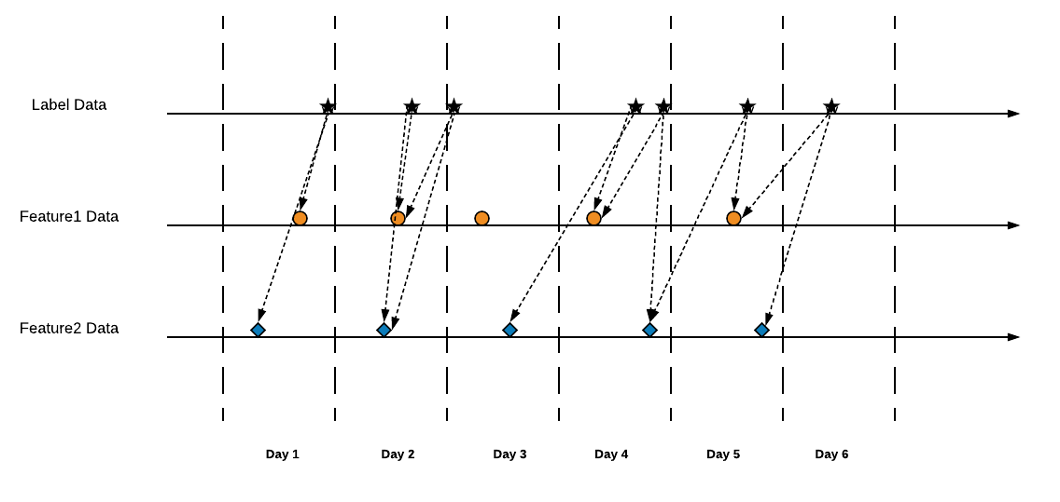
在上面的示例中,我们使用“LATEST”作为聚合类型。“LATEST”表示在窗口中获取最新(最接近样本时间戳)的特征数据。对于所有其他窗口聚合类型,也会保证时间点的正确性。例如,在“SUM”中,我们仅对窗口中最接近并早于样本时间戳的数据求和。