本文通过将图片和代码结合的方式,讲解 YOLOv8 目标检测中的 Anchor-Free 机制。(本文正在更新中,欢迎在底部提出宝贵意见)
本文内容
背景知识
锚框(Anchor)
Anchor 指有固定中心位置和大小(通常由宽度和高度决定)的框。Anchor 思想最早在论文 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks (2015.06,Microsoft) 中提出。在此之前,目标检测算法通常使用滑动窗口或 Selective Search 等方法来生成候选区域。而 Faster R-CNN 中的 RPN(Region Proposal Network)网络通过引入 Anchor 机制,解决了目标检测算法中目标大小和长宽比的变化问题。
Faster R-CNN 中的 Anchor 设计如下:
- 通过在 feature map 的每个像素位置设置不同大小和长宽比的 Anchor,算法能够更准确地拟合图片中不同大小的目标可能存在的位置。
- 每个 Anchor 都被视为一个可能的候选区域,算法会计算每个 Anchor 与真实目标框(GT)的交并比(IOU),并根据 IOU 值来确定 Anchor 是否为正样本或负样本。
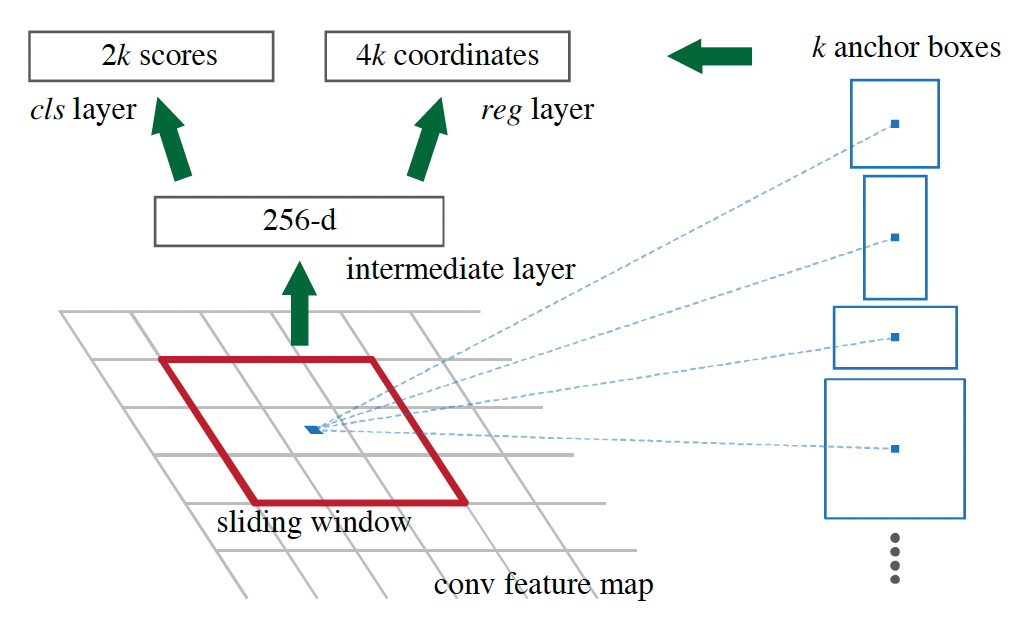 Region Proposal Network (RPN) 中提出了 Anchor 方法(图片来源于 Faster R-CNN 论文)
Region Proposal Network (RPN) 中提出了 Anchor 方法(图片来源于 Faster R-CNN 论文)
注意锚框和 GT 框的区别:
- 锚框是机器学习过程中模型预测(或者预设)的,而 GT 框是指人工标记的图片框。
- 锚框是基于特征图,而 GT 框基于图片的像素(当然两者可以非常粗略地对应上,但表示的含义是不一样的)。
通常在训练过程中,通过和 GT 框的比对,把锚框定义为正样本和负样本(详见后面的标签分配章节)。
Anchor-Based 和 Anchor-Free
Two-stage(两阶段)指目标检测过程分成两个主要步骤:
- 生成候选区域(Region Proposals),来确定图像中可能包含对象的区域。
- 对第 1 阶段生成的候选区域进行分类和边界框细化。
Anchor-based(基于锚框)指在目标检测中使用一组预定义的、不同尺寸和比例的候选区域(anchors),用于引导检测模型学习到真实的对象边界框。
Anchor-Free 并不是没有使用锚点,而是指无先验锚框,直接通过预测具体的点得到锚框。Anchor-Free 不需要手动设计 anchor(长宽比、尺度大小、anchor的数量),从而避免了针对不同数据集进行繁琐的设计。
不同的 Anchor 方案总结如下:
- anchor-based
- two-stage
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
(2015.06,Microsoft) :在 feature map 上滑动窗口,人工设计不同尺寸的 anchor(a pyramid of anchors)。
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- one-stage
- SSD: Single-Shot MultiBox Detector
(2015.12,UNC Chapel Hill 等)
- RetinaNet,论文:Focal Loss for Dense Object Detection
(2017.08,Meta)
- SSD: Single-Shot MultiBox Detector
- two-stage
- anchor-free
- keypoint-based
- CornerNet: Detecting Objects as Paired Keypoints
(2018.08,-)
- CenterNet: Keypoint Triplets for Object Detection
(2019.04,-)
- CornerNet: Detecting Objects as Paired Keypoints
- center-based
- YOLOv1,论文:You Only Look Once: Unified, Real-Time Object Detection
(2015.06,华盛顿大学)
- FCOS: Fully Convolutional One-Stage Object Detection
(2019.04,-)
- YOLOX: Exceeding YOLO Series in 2021
(2021.07,旷视)
- YOLOv1,论文:You Only Look Once: Unified, Real-Time Object Detection
- keypoint-based
正样本和负样本
正样本(positive sample)和负样本(negative sample)是用于训练分类模型的两种基本类型的数据点。
在目标检测中,正样本是指锚框中恰当地包含我们希望检测的目标对象的样本。例如,在行人检测任务中,如果锚框中确实有行人,且框大小合适,那么这个框就是一个正样本。负样本指锚框中可能没有目标检测对象,或者框大小不合适。
在目标检测任务中,负样本的引入也是至关重要的。在真实世界的图像中,目标往往只占图像的一小部分区域,而大部分区域都是背景(即负样本)。如果模型仅使用正样本来训练,它可能会过度拟合到这些有限的目标样本,而无法正确地区分目标和背景。通过引入负样本,模型能够学习到目标的边界,并理解哪些区域不包含目标。
通常,目标检测任务使用锚点(anchor boxes)而不是直接使用真实目标(ground truth boxes,人工标记的物体框选)作为正负样本,有几个重要原因:
- 正负样本平衡:直接使用真实目标作为目标值可能导致训练过程中的样本不平衡问题,因为背景区域通常远多于目标区域。通过使用锚点,可以更有效地分配正样本(匹配真实目标的锚点)和负样本(不匹配任何真实目标的锚点),从而帮助模型更好地学习。
- 泛化能力:如果直接使用真实目标作为目标值,模型可能过于依赖于训练数据中的具体实例,从而降低其泛化到新数据的能力。使用锚点可以帮助模型学习到更一般化的目标表示。
- 边界框回归:在训练过程中,模型需要学习如何调整预测的边界框以更好地匹配真实目标。如果直接使用真实目标作为目标值,模型将无法学习到如何进行这种调整。锚点提供了一个起点,模型可以学习从这个起点调整边界框以适应真实目标。
任务对齐(Task Alignment)
目标检测旨在从自然图像中定位和识别感兴趣的对象,它通常被表述为一个多任务学习问题,通过同时优化对象分类和定位来实现。分类任务旨在学习对象的关键区分性特征,而定位任务则致力于精确定位整个对象及其边界。由于分类和定位任务的学习机制存在差异,这两个任务所学到的特征的空间分布可能不同,当使用两个独立分支进行预测时,可能会导致一定程度的错位。
YOLOv8 目标检测的 Anchor 处理
训练阶段的主要处理逻辑如下:
- 在 Head 部分(参考 YOLOv8 架构图),会输出三个特征图(以 YOLOv8 L 为例,特征图大小分别为:80 x 80 x 256,40 x 40 x 512,1. 20 x 20 x 512)。
- 每个特征图上的每个点,会定义为 1 个锚框(anchor),模型的输出预测值中包括每个锚框的分类和定位信息。
- 标签分配算法:根据人工标记的 GT,将每个 anchor 对应为正、负样本。
- 依据损失函数,计算正、负样本的损失,反向传播更新网络参数。
推理阶段的主要处理逻辑如下:待补充。
【原作者的解释 1】Is YOLOv8 a anchor-free detector?
尽管 YOLOv8 在检测(推理)阶段被归类为无锚点模型,因为它不依赖于预定义的锚框。
- 在训练阶段,它仍然使用了锚点的概念。这些“锚点”作为边界框的尺度和长宽比的初始估计或参考。在训练过程中,模型根据训练图像中对象的真实边界框来调整和优化这些估计。
- 在检测阶段,模型并不严格依赖预定义的锚框来提出候选对象位置,最终的对象检测是直接基于检测到的特征进行的,因此 YOLOv8 被归类为无锚点(anchor-free)模型。
could you please explain what is the purpose of the make_anchors() function if YOLOv8 is an anchor free detection model?
Even though YOLOv8 is categorized as an anchor-free model in the sense that it does not rely on pre-defined anchor boxes during the detection phase, it still uses a concept of anchors during the training phase. The make_anchors() function plays a crucial role here.
In the case of YOLOv8, these “anchors” serve as initial estimates or references for the scale and aspect ratios of the bounding boxes. During training, the model learns to adjust and refine these estimates based on the ground truth bounding boxes of the objects in the training images.
So, while the model doesn’t strictly use pre-defined anchor boxes to propose candidate object locations during detection, the concept of anchors is used to initialize and guide the training process. The final object detections are done directly from the detected features, thus qualifying YOLOv8 as an anchor-free model.
【原作者的解释 2】Brief summary of YOLOv8 model structure
YOLOv8 将输入图像分割成单元格网格,其中每个单元格负责预测位于其中的对象。对于每个单元格,YOLOv8 预测对象得分(objectness scores)、类别概率(class probabilities)和几何偏移量(geometrical offsets),以便估计对象的边界框。
I suggest reading the FCOS and YOLOX papers to get a better understanding of anchor-free object detection methods and how they differ from traditional anchor-based methods.
YOLOv8 does use an anchor-free approach similar to YOLOX for object detection. Instead of predefined anchors or bounding boxes, YOLOv8 divides the input image into a grid of cells, where each cell is responsible for predicting the object(s) located inside it. For each cell, YOLOv8 predicts objectness scores, class probabilities, and geometrical offsets to estimate the bounding box of the object.
The geometrical offsets are predicted relative to the center of the cell, as in YOLOX, allowing the model to localize objects without relying on predefined anchors or reference points. The total number of predicted bounding boxes depends on the size of the grid and the number of anchor boxes used for each cell.
【模型训练】标签分配(Label Assignment)
如 ATSS 论文中分析,如何定义正、负训练样本(Label Assignment)非常关键。
主要标签分配方法如下。
- Adaptive Training Sample Selection (ATSS),论文:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
(2019.12,中国科学院自动化研究所)
- simOTA,出自 YOLOX
- Task Alignment Learning (TAL),论文:TOOD: Task-aligned One-stage Object Detection
(2021.08,云天励飞、美团)
ATSS 算法(参考)
标签分配部分,YOLOv8 中用到的 TAL 算法,很多地方类似 ATSS,下面简要介绍一下 ATSS。
论文主要点:
- 正、负样本的选择非常关键
- ATSS 方法几乎不需要任何超参数,就可以根据对象的统计特性自动划分正负样本。
ATSS 算法处理过程如下:
- 对于图像上的每个真实边界框 ,首先找出其候选正样本。如第3至6行所述,在每个金字塔层级上,基于 L2 距离选择 个锚框,这些锚框的中心与 的中心最接近。假设有 个特征金字塔层级,则真实边界框 将有 个候选正样本。
- 计算这些候选样本与真实边界框 的交并比(IoU),记作 (第 7 行),并计算其均值 (第8行)和标准差 (第 9 行)。基于这些统计信息,真实边界框 的 IoU 阈值 在第10行中得出,即 。
- 最后,选择 IoU 大于或等于阈值 的候选样本作为最终的正样本(第 11 至 15 行)。当然,正样本的中心需要位于真实边界框内(第 12 行)。
- 如果一个锚框被分配给多个真实边界框,将选择 IoU 最高的那个,其余的为负样本。
 ATSS 算法,图片来源于论文 arXiv:1912.02424
ATSS 算法,图片来源于论文 arXiv:1912.02424
TAL 算法(YOLOv8 使用)
参考代码 utils/tal.py(TaskAlignedAssigner)。Task-aligned 指分类任务和目标框任务对齐。
对齐的衡量指标
如下为对齐指标的计算公式:
其中, 和 分别表示分类得分和 IoU 值。(YOLOv8 中默认为 0.5) 和 (YOLOv8 默认为 6.0)用于控制在锚点对齐指标中两个任务(分类和定位)的影响。
tal.py 中的参考代码:
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
训练样本分配
一个简单的分配规则来选择训练样本:对于每个 GT 实例,我们选择 个具有最大 值的锚点作为正样本,而将剩余的锚点作为负样本。
预测框的设计及损失函数(DFL)
YOLOv8 使用 DFL 衡量预测框的损失。
如何表示偏移量
 Distribution Focal Loss (DFL) 采用从锚点到边界框四边的相对偏移量作为回归目标,单个偏移量用一般分布(General distribution)表示。
Distribution Focal Loss (DFL) 采用从锚点到边界框四边的相对偏移量作为回归目标,单个偏移量用一般分布(General distribution)表示。
假定标签 的范围,其最小值为 ,最大值为 (),DFL 将整个范围 离散成一个集合 ,以步长 1 递增。以目标检测框的偏移量为例,YOLOv8 代码中取 reg_max=16,则离散的集合为 ,模型实质上是预测偏移量落在 0~15 每个整数的概率,所有整数点的概率求和等于 1。
设定离散分布满足 ,则预估的回归值可以写成:
这样, 可以用一个包含 个节点的 softmax 层(将一组数值转换为概率的经典实现,背景知识可以参考 什么是logit)实现。
如何计算损失?
选取最接近 的两个值,,DFL 公式如下:
YOLOv8 中的代码示例
YOLOv8 模型对框的预测和训练都是基于 anchor 及偏移量。如下方法用于转换。
# 来自文件 utils/tal.py
def bbox2dist(anchor_points, bbox, reg_max):
"""Transform bbox(xyxy) to dist(ltrb).
将框由 xyxy 坐标形式变成相对锚点的偏移量形式(左上右下)。
anchor_points 为坐标点,如对于长宽为 8*5 的图,
[[0,0],[1,0], ..., [7,0],
[0,1], [1,1], ..., [7,1],
[0,2], [1,2], ..., [7,2],
[0,3], [1,3], ..., [7,3],
[0,4], [1,4], ..., [7,4]]
基于 torch 的维度自动扩展,anchor_points 方便锚点位置转换的计算
"""
x1y1, x2y2 = bbox.chunk(2, -1) # 最后一个维度 [x1, y1, x2, y2],分成 2 份,变成 [x1, y1] [x2,y2]。前面的维度不变。
# 先计算左、上、右、下的偏移量,然后将其取值范围压缩(clamp_) 到 [0, reg_max - 0.01] 之间
return torch.cat((anchor_points - x1y1, x2y2 - anchor_points), -1).clamp_(0, reg_max - 0.01) # dist (lt, rb)
def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
"""Transform distance(ltrb) to box(xywh or xyxy)."""
lt, rb = distance.chunk(2, dim)
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
if xywh:
c_xy = (x1y1 + x2y2) / 2
wh = x2y2 - x1y1
return torch.cat((c_xy, wh), dim) # xywh bbox
return torch.cat((x1y1, x2y2), dim) # xyxy bbox
根据 YOLOv8 的 Detect 头输出,生成锚点。
# 来自文件 utils/tal.py
def make_anchors(feats, strides, grid_cell_offset=0.5):
"""Generate anchors from features.
feats 为模型预测值,对于 Detect 任务,head.py 中 Detect 的输出为(x0,x1,x2),x[0]的shape(N, reg_max*4+nc , H, W)
输出 anchor_points 为坐标点的集合,包括(x0,x1,x2)H,W 对应的所有坐标。
"""
anchor_points, stride_tensor = [], []
assert feats is not None
dtype, device = feats[0].dtype, feats[0].device
for i, stride in enumerate(strides):
_, _, h, w = feats[i].shape
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y
sy, sx = torch.meshgrid(sy, sx, indexing="ij") if TORCH_1_10 else torch.meshgrid(sy, sx)
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
return torch.cat(anchor_points), torch.cat(stride_tensor)
# 来自文件 utils/loss.py
class BboxLoss(nn.Module):
"""Criterion class for computing training losses during training."""
def __init__(self, reg_max, use_dfl=False):
"""Initialize the BboxLoss module with regularization maximum and DFL settings."""
super().__init__()
self.reg_max = reg_max
self.use_dfl = use_dfl
def forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):
"""IoU loss."""
weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)
iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)
loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum
# DFL loss
if self.use_dfl:
target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)
loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weight
loss_dfl = loss_dfl.sum() / target_scores_sum
else:
loss_dfl = torch.tensor(0.0).to(pred_dist.device)
return loss_iou, loss_dfl
@staticmethod
def _df_loss(pred_dist, target):
"""
Return sum of left and right DFL losses.
Distribution Focal Loss (DFL) proposed in Generalized Focal Loss
https://ieeexplore.ieee.org/document/9792391
Args:
pred_dist (Tensor): shape(bs * num_total_anchors * 4, self.reg_max + 1)
target (Tensor): shape(bs * num_total_anchors * 4,)(待确认)
"""
tl = target.long() # target left,对应 DFL 公式的 y_i
tr = tl + 1 # target right,对应 DFL 公式的 y_{i+1}
wl = tr - target # weight left,公式第 1 项的权重,对应 DFL 公式的 y_{i+1} - y
wr = 1 - wl # weight right,公式第 2 项的权重,对应 DFL 公式的 y - y_i
return (
F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl # log(P_i) * wl
+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr # log(P_{i+1})) * wr
).mean(-1, keepdim=True)
【模型训练】YOLOv8 相关代码逻辑
整体调用流程
参考 架构图 Detect Head 部分 理解损失函数计算前的网络输出。
下面以目标检测为例,说明 YOLOv8 中训练过程中的损失函数计算。
整体调用过程如下(参考代码文件 nn/task.py):
- 模型在训练 forward() 时,会调用 self.loss()
- loss() 函数逻辑如下:
- 第一次调用时,通过 init_criterion() 初始化损失函数模块 v8DetectionLoss(详细见后)
- 计算损失,供模型训练的反向传播更新参数用。(注:关于训练整体框架,通用类见 engine/trainer.py 中的 BaseTrainer 类,具体模型类见 models/yolo/detect/train.py 中的 DetectionTrainer 类)。
class BaseModel(nn.Module):
"""The BaseModel class serves as a base class for all the models in the Ultralytics YOLO family."""
def forward(self, x, *args, **kwargs):
"""
Forward pass of the model on a single scale. Wrapper for `_forward_once` method.
Args:
x (torch.Tensor | dict): The input image tensor or a dict including image tensor and gt labels.
Returns:
(torch.Tensor): The output of the network.
"""
if isinstance(x, dict): # for cases of training and validating while training.
return self.loss(x, *args, **kwargs)
return self.predict(x, *args, **kwargs)
# ...... 此处省略大量代码 ......
def loss(self, batch, preds=None):
"""
Compute loss.
Args:
batch (dict): Batch to compute loss on
preds (torch.Tensor | List[torch.Tensor]): Predictions.
"""
if not hasattr(self, "criterion"):
self.criterion = self.init_criterion()
preds = self.forward(batch["img"]) if preds is None else preds
return self.criterion(preds, batch)
def init_criterion(self):
"""Initialize the loss criterion for the BaseModel."""
raise NotImplementedError("compute_loss() needs to be implemented by task heads")
class DetectionModel(BaseModel):
"""YOLOv8 detection model."""
# ...... 此处省略大量代码 ......
def init_criterion(self):
"""Initialize the loss criterion for the DetectionModel."""
return v8DetectionLoss(self)
损失函数计算
v8DetectionLoss(见文件:utils/loss.py)的调用逻辑如下。
- 标签分配,调用 TaskAlignedAssigner 将预测值对应到 GT
- 调用 BCE 计算分类损失
- 调用 BboxLoss 完成计算。
- 计算 IOU 损失
use_dfl = True时,会计算 DFL
class v8DetectionLoss:
"""Criterion class for computing training losses."""
def __init__(self, model): # model must be de-paralleled
"""Initializes v8DetectionLoss with the model, defining model-related properties and BCE loss function."""
device = next(model.parameters()).device # get model device
h = model.args # hyperparameters
m = model.model[-1] # Detect() module
self.bce = nn.BCEWithLogitsLoss(reduction="none")
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.no = m.nc + m.reg_max * 4 # 上一个 Module 返回的通道数量
self.reg_max = m.reg_max
self.device = device
self.use_dfl = m.reg_max > 1
self.assigner = TaskAlignedAssigner(topk=10, num_classes=self.nc, alpha=0.5, beta=6.0)
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=self.use_dfl).to(device)
# 生成 0 到 reg_max-1(reg_max 取值 16)的整数列表,详见“如何表示偏移量”章节
self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)
def preprocess(self, targets, batch_size, scale_tensor):
"""Preprocesses the target counts and matches with the input batch size to output a tensor."""
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
counts = counts.to(dtype=torch.int32)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
"""Decode predicted object bounding box coordinates from anchor points and distribution."""
if self.use_dfl: # 不使用偏移量的绝对值,而是用一般分布表示。
b, a, c = pred_dist.shape # batch, anchors, channels
# 对最后一维(reg_max)做 softmax 转换成映射表 [0,15] 中每个整数的概率,再乘以映射表,得到均值,作为该锚点的某个偏移量的预估值。
# pred_dist 变为 shape(batch, anchors, 4)
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, preds, batch):
"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size.
batch 为训练批次 dict(待确认),其中包括 GT 的 batch_idx, cls,bboxes 等属性"""
loss = torch.zeros(3, device=self.device) # box, cls, dfl
# # Detect 推理时返回(y,x),训练时返回 x,故这里根据返回类型提取特征。
# feats 为模型预测值,对于 Detect 任务,head.py 中 Detect 的输出为(x0,x1,x2),x[0]的shape(N, reg_max*4+nc , H, W)
feats = preds[1] if isinstance(preds, tuple) else preds
# pred_distri 的形状为(N, reg_max*4, 锚点数为3个h*w的和)
# pred_scores 的形状为(N, nc, 锚点数为3个h*w的和)
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1
)
# nn.Conv2d的维度是(N, C, H, W),为了后续方便基于锚点处理,这里维度顺序改变:
# pred_scores 的形状变为(N, 锚点数为3个h*w的和,nc)
# pred_distri 的形状变为(N, 锚点数为3个h*w的和,reg_max*4)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size = pred_scores.shape[0]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# Targets
targets = torch.cat((batch["batch_idx"].view(-1, 1), batch["cls"].view(-1, 1), batch["bboxes"]), 1)
targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# Pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
_, target_bboxes, target_scores, fg_mask, _ = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt,
)
target_scores_sum = max(target_scores.sum(), 1)
# Cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
# Bbox loss
if fg_mask.sum():
target_bboxes /= stride_tensor
loss[0], loss[2] = self.bbox_loss(
pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask
)
loss[0] *= self.hyp.box # box gain
loss[1] *= self.hyp.cls # cls gain
loss[2] *= self.hyp.dfl # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)
TAL 代码注释
# 来自文件 ultralytics/utils/tal.py
import torch
import torch.nn as nn
from .metrics import bbox_iou
class TaskAlignedAssigner(nn.Module):
"""
A task-aligned assigner for object detection.
This class assigns ground-truth (gt) objects to anchors based on the task-aligned metric, which combines both
classification and localization information.
Attributes:
topk (int): The number of top candidates to consider.
num_classes (int): The number of object classes.
alpha (float): The alpha parameter for the classification component of the task-aligned metric.
beta (float): The beta parameter for the localization component of the task-aligned metric.
eps (float): A small value to prevent division by zero.
"""
def __init__(self, topk=13, num_classes=80, alpha=1.0, beta=6.0, eps=1e-9):
"""Initialize a TaskAlignedAssigner object with customizable hyperparameters."""
super().__init__()
self.topk = topk
self.num_classes = num_classes
self.bg_idx = num_classes # 背景的类别编号
self.alpha = alpha
self.beta = beta
self.eps = eps
@torch.no_grad()
def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):
"""
Compute the task-aligned assignment.
Args:
pd_scores (Tensor): shape(bs, num_total_anchors, num_classes),预测分类,锚点属于每一个分类的概率。
pd_bboxes (Tensor): shape(bs, num_total_anchors, 4),预测偏移量,已经从 DFL 的一般分布转为标量(Scalar)。
anc_points (Tensor): shape(num_total_anchors, 2),辅助 Tensor,方便锚点偏移量和框坐标的转换。
gt_labels (Tensor): shape(bs, n_max_boxes, 1),人工标记的 GT 框对应的分类编号
gt_bboxes (Tensor): shape(bs, n_max_boxes, 4),人工标记的 GT 框坐标,xyxy
mask_gt (Tensor): shape(bs, n_max_boxes, 1),由于 GT 框数量一般少于 n_max_boxes, 向量运算一般基于同一形状,该变量表示 gt_bboxes 的位置是否有真实 GT 还是空位补齐。(待确认)
Returns:
target_labels (Tensor): shape(bs, num_total_anchors)
target_bboxes (Tensor): shape(bs, num_total_anchors, 4)
target_scores (Tensor): shape(bs, num_total_anchors, num_classes)
fg_mask (Tensor): shape(bs, num_total_anchors)
target_gt_idx (Tensor): shape(bs, num_total_anchors)
"""
self.bs = pd_scores.shape[0]
self.n_max_boxes = gt_bboxes.shape[1]
# ...... 此处省略部分代码 ......
mask_pos, align_metric, overlaps = self.get_pos_mask(
pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt
)
target_gt_idx, fg_mask, mask_pos = self.select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)
# Assigned target
target_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)
# Normalize
align_metric *= mask_pos
pos_align_metrics = align_metric.amax(dim=-1, keepdim=True) # b, max_num_obj
pos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True) # b, max_num_obj
norm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)
target_scores = target_scores * norm_align_metric
return target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):
# 初步筛选:对每一个 GT 框,生成掩码锚点图(也就是说,获取锚点是否在任一 GT 内的掩码,不涉及预测值)。
# 返回 shape(b, max_num_obj, h*w)
mask_in_gts = self.select_candidates_in_gts(anc_points, gt_bboxes)
# 获取锚点预测值和 GT 框的对齐分数及 IOU 值。
# 返回 shape(b, max_num_obj, h*w)
align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_in_gts * mask_gt)
# Get topk_metric mask, (b, max_num_obj, h*w)
mask_topk = self.select_topk_candidates(align_metric, topk_mask=mask_gt.expand(-1, -1, self.topk).bool())
# Merge all mask to a final mask, (b, max_num_obj, h*w)
mask_pos = mask_topk * mask_in_gts * mask_gt
return mask_pos, align_metric, overlaps
def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt):
"""Compute alignment metric given predicted and ground truth bounding boxes.
(计算所有预测框和 GT 框的对齐分数、CIoU值,已经通过锚点在 GT 框内过滤)
Args:
pd_scores (Tensor): shape(bs, num_total_anchors, num_classes),预测分类,锚点属于每一个分类的概率。
"""
na = pd_bboxes.shape[-2] # num_total_anchors,锚点数量
mask_gt = mask_gt.bool() # (b, max_num_obj, h*w)
overlaps = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_bboxes.dtype, device=pd_bboxes.device)
# 初始化为 0。 bbox_scores (Tensor): shape(bs, n_max_boxes, na),注意,形状和 pd_scores 不相同。
bbox_scores = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_scores.dtype, device=pd_scores.device)
ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long) # 2, b, max_num_obj
# 【方便理解代码的示例】
# 代码:torch.arange(end=3).view(-1, 1).expand(-1, 4)
# 返回:tensor([[0, 0, 0, 0],
# [1, 1, 1, 1],
# [2, 2, 2, 2]])
# 返回 (b, max_num_obj)
ind[0] = torch.arange(end=self.bs).view(-1, 1).expand(-1, self.n_max_boxes)
# gt_labels (Tensor): shape(bs, n_max_boxes, 1)。对最后一个维度挤压后,返回 (b, max_num_obj)
ind[1] = gt_labels.squeeze(-1)
# Get the scores of each grid for each gt cls
bbox_scores[mask_gt] = pd_scores[ind[0], :, ind[1]][mask_gt] # (b, max_num_obj, h*w)
# pd_bboxes.unsqueeze(1): unsqueeze 操作用于增加一个维度。这里在索引为1的位置增加一个维度,使得 pd_bboxes 的形状从 (bs, h*w, 4) 变为 (bs, 1, h*w, 4)。
# .expand(-1, self.n_max_boxes, -1, -1): expand 操作用于扩展张量的形状。参数 -1 表示该维度保持原样不变。因此,这个操作将 (bs, 1, h*w, 4) 形状的张量扩展为 (bs, n_max_boxes, h*w, 4)。
# [mask_gt]: 最后,使用 mask_gt 张量作为索引来选择 expand 后张量中对应位置的元素。mask_gt 是一个布尔型张量,形状为 (bs, n_max_boxes, h*w),其中 True 表示相应的锚点与某个真实目标匹配,False 表示不匹配。这个索引操作将 (bs, n_max_boxes, h*w, 4) 形状的张量中不匹配的位置(即 False 位置)设置为0(因为在前面创建的 overlaps 和 bbox_scores 中使用了 torch.zeros),而匹配的位置则保留了扩展后的值。
pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, self.n_max_boxes, -1, -1)[mask_gt]
# 扩展后和 pd_boxes 形状一致。
gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[mask_gt]
# 计算预测框和 GT 框的 iou 得分
overlaps[mask_gt] = self.iou_calculation(gt_boxes, pd_boxes)
# 最终的对齐分数。参考论文 2108.07755 - 3.2.1 Task-aligned Sample Assignment。
align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta)
# 每个 GT 框在锚点图上的的对齐得分、重叠度, shape(b, max_num_obj, na)
return align_metric, overlaps
def iou_calculation(self, gt_bboxes, pd_bboxes):
"""IoU calculation for horizontal bounding boxes."""
return bbox_iou(gt_bboxes, pd_bboxes, xywh=False, CIoU=True).squeeze(-1).clamp_(0)
def select_topk_candidates(self, metrics, largest=True, topk_mask=None):
"""
Select the top-k candidates based on the given metrics.(对每个 GT 框,根据对齐分数,选取 topk 个锚点)
Args:
metrics (Tensor): A tensor of shape (b, max_num_obj, h*w), where b is the batch size,
max_num_obj is the maximum number of objects, and h*w represents the
total number of anchor points.
largest (bool): If True, select the largest values; otherwise, select the smallest values.
topk_mask (Tensor): An optional boolean tensor of shape (b, max_num_obj, topk), where
topk is the number of top candidates to consider. If not provided,
the top-k values are automatically computed based on the given metrics.
Returns:
(Tensor): A tensor of shape (b, max_num_obj, h*w) containing the selected top-k candidates.
"""
# (b, max_num_obj, topk)
topk_metrics, topk_idxs = torch.topk(metrics, self.topk, dim=-1, largest=largest)
if topk_mask is None:
topk_mask = (topk_metrics.max(-1, keepdim=True)[0] > self.eps).expand_as(topk_idxs)
# (b, max_num_obj, topk)
topk_idxs.masked_fill_(~topk_mask, 0)
# (b, max_num_obj, topk, h*w) -> (b, max_num_obj, h*w)
count_tensor = torch.zeros(metrics.shape, dtype=torch.int8, device=topk_idxs.device)
ones = torch.ones_like(topk_idxs[:, :, :1], dtype=torch.int8, device=topk_idxs.device)
for k in range(self.topk):
# Expand topk_idxs for each value of k and add 1 at the specified positions
count_tensor.scatter_add_(-1, topk_idxs[:, :, k : k + 1], ones)
# count_tensor.scatter_add_(-1, topk_idxs, torch.ones_like(topk_idxs, dtype=torch.int8, device=topk_idxs.device))
# Filter invalid bboxes
count_tensor.masked_fill_(count_tensor > 1, 0)
return count_tensor.to(metrics.dtype)
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):
"""
Compute target labels, target bounding boxes, and target scores for the positive anchor points.
Args:
gt_labels (Tensor): Ground truth labels of shape (b, max_num_obj, 1), where b is the
batch size and max_num_obj is the maximum number of objects.
gt_bboxes (Tensor): Ground truth bounding boxes of shape (b, max_num_obj, 4).
target_gt_idx (Tensor): Indices of the assigned ground truth objects for positive
anchor points, with shape (b, h*w), where h*w is the total
number of anchor points.
fg_mask (Tensor): A boolean tensor of shape (b, h*w) indicating the positive
(foreground) anchor points.
Returns:
(Tuple[Tensor, Tensor, Tensor]): A tuple containing the following tensors:
- target_labels (Tensor): Shape (b, h*w), containing the target labels for
positive anchor points.
- target_bboxes (Tensor): Shape (b, h*w, 4), containing the target bounding boxes
for positive anchor points.
- target_scores (Tensor): Shape (b, h*w, num_classes), containing the target scores
for positive anchor points, where num_classes is the number
of object classes.
"""
# Assigned target labels, (b, 1)
batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]
target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)
target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)
# Assigned target boxes, (b, max_num_obj, 4) -> (b, h*w, 4)
target_bboxes = gt_bboxes.view(-1, gt_bboxes.shape[-1])[target_gt_idx]
# Assigned target scores
target_labels.clamp_(0)
# 10x faster than F.one_hot()
target_scores = torch.zeros(
(target_labels.shape[0], target_labels.shape[1], self.num_classes),
dtype=torch.int64,
device=target_labels.device,
) # (b, h*w, 80)
target_scores.scatter_(2, target_labels.unsqueeze(-1), 1)
fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)
target_scores = torch.where(fg_scores_mask > 0, target_scores, 0)
return target_labels, target_bboxes, target_scores
@staticmethod
def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):
"""
Select the positive anchor center in gt.
选择在 GT 内的锚点中心,用作正样本。即对每一个 GT 框,生成掩码锚点图。
Args:
xy_centers (Tensor): shape(h*w, 2),锚点中心坐标,不涉及模型预测值
gt_bboxes (Tensor): shape(b, n_boxes, 4)
Returns:
(Tensor): shape(b, n_boxes, h*w),一个布尔型张量,其中True表示对应的锚点中心位于对应的真实目标内,False则表示不在内。
"""
n_anchors = xy_centers.shape[0] # 锚点总数
bs, n_boxes, _ = gt_bboxes.shape # 获取批次大小bs和每个图片中真实目标的数量 n_boxes
# 将 gt_bboxes 拆分为左上角坐标 lt 和右下角坐标 rb
# lt (Tensor): shape(b*n_boxes, 1, 2)
lt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # left-top, right-bottom
# 计算了每个锚点中心相对于每个 GT 左上角的差值以及每个 GT 右下角与锚点中心的差值,小于 0 表示不在框内。
# xy_centers[None] (Tensor):shape(1, h*w, 2)
# xy_centers[None] - lt (Tensor): shape(b*n_boxes, h*w, 2),这里用到了第 0、1 维度的自动扩展(即广播)。
# bbox_deltas (Tensor): shape(b, n_boxes, n_anchors, 4),
bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1)
# amin(3)要求所有 4 个比对值都必须大于 0
return bbox_deltas.amin(3).gt_(eps)
@staticmethod
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):
"""
If an anchor box is assigned to multiple gts, the one with the highest IoU will be selected.
Args:
mask_pos (Tensor): shape(b, n_max_boxes, h*w)
overlaps (Tensor): shape(b, n_max_boxes, h*w)
Returns:
target_gt_idx (Tensor): shape(b, h*w)
fg_mask (Tensor): shape(b, h*w)
mask_pos (Tensor): shape(b, n_max_boxes, h*w)
"""
# (b, n_max_boxes, h*w) -> (b, h*w)
fg_mask = mask_pos.sum(-2) # 对每一个锚点,统计对应的 GT 总数
if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes
mask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1) # (b, n_max_boxes, h*w)
max_overlaps_idx = overlaps.argmax(1) # (b, h*w)
is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)
is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1)
mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float() # (b, n_max_boxes, h*w)
fg_mask = mask_pos.sum(-2)
# Find each grid serve which gt(index)
target_gt_idx = mask_pos.argmax(-2) # (b, h*w)
return target_gt_idx, fg_mask, mask_pos
发布于:2024-05-28 描述有误?我来纠错